Solution Pattern: Using Change Data Capture for Stack Modernization
Architecture
1. Common Challenges when Extending Stack Capabilities
To better explain and detail the reasons for the existence of this solution pattern we’ll picture some common needs and challenges amongst organizations that already have production systems and seeks innovation and modernization.
1.1. Distributed Systems and Data Access
In a distributed system it’s common to have services that must use data owned by other services to deliver its capabilities.
First challenge
Currently, there is a production legacy retail service that persists all sales and inventory data in a single database. The challenge is now to deliver a cashback capability that is highly dependent on the retail data, leveraging modern technology and architecture design best practices.
At a first glance, a simple solution to such complex problem would be to implement the cashback service with its own database for cashback domain data, and directly accessing retail database to obtain and update sales information.
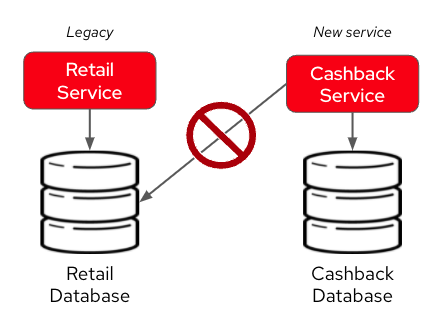
Unfortunately, this is an anti-pattern for data access and management in a distributed architecture. Multiple services should not consume and change data directly in databases owned by other services.
1.2. The need to store data in multiple data stores
Another modernization challenge is enhancing search capabilities in huge set of data, improving efficiency by increasing search response time, reducing number of disk accesses, using efficient search algorithms and being able to scale according to demand. To address such problem, we could complement the retail service by adding a search index like Elasticsearch.
Second challenge
In other to start consuming search capabilities from tools like Elasticsearch, the first step is to feed data into the tool’s index. This process is called indexing. All the queryable data needs to be pushed to the tool’s storage, the index (Apache Lucene).
The production stack is based on the retail service that currently persists data to a single database. The challenge is to make all the retail data searchable through a tool like Elasticsearch.
One could think about changing the service to push the data not only to its own database, but also to ElasticSearch. It becomes a distributed system where the core data operations are no longer handled in single transactions. Be aware: this is yet another anti-pattern, called dual write.
| Dual writes can cause data inconsistency problems for distributed systems. |
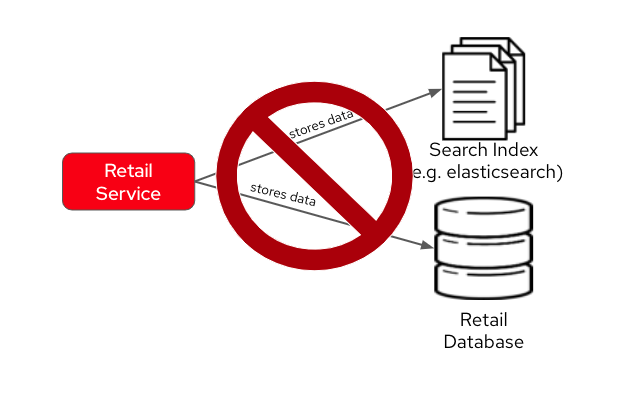
The consequence of issues in this solution would be to have an outdated data being queried by the user, in other words, a user could potentially see an item for sale that is no longer available, or see a list of items with an outdated price.
Other than data inconsistency, changes to the legacy application would be required. Such changes are not always possible either for business or technological restrictions.
1.2.1. Avoid Antipatterns
Think twice before delivering solutions with antipatterns. Here’s a summary of the two antipatterns we’ve seen so far:
- Shared databases
-
Multiple services are linked through a single database.
- Dual write
-
A situation when a service inserts and/or changes data in two or more different data stores or systems. (e.g. database and search index or a distributed cache).
2. Technology Stack
-
Red Hat Application Foundation
-
Other:
3. An in-depth look at the solution’s architecture
The whole solution builds upon the event streams flowing for each change on the database. The data integration is the enabler for all the new services to execute their respective operations.
The following diagram represents an abstract architectural view of the system scope, personas involved, the multiple apps and storage:
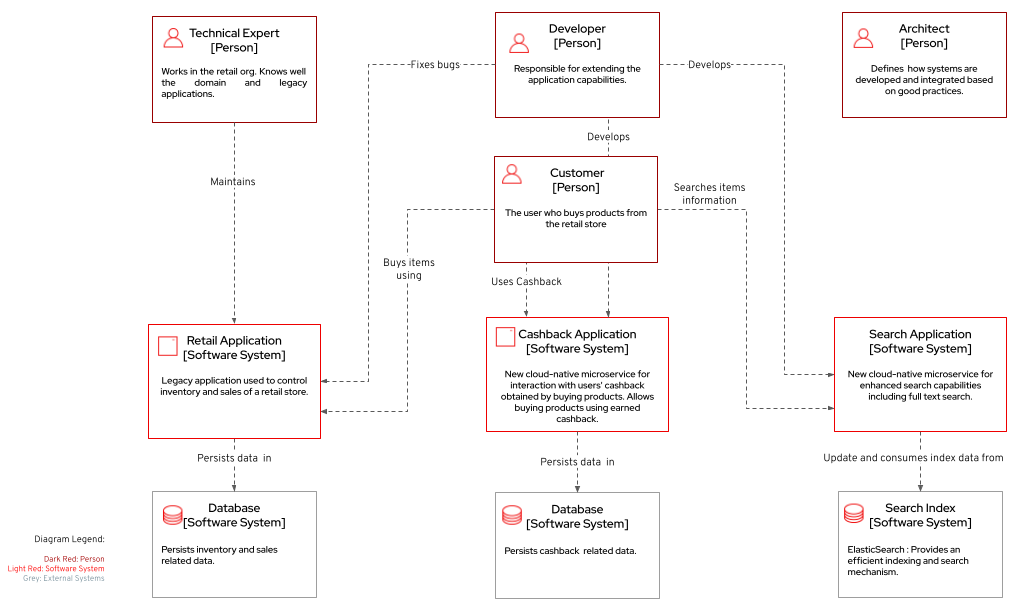
Three main application contexts are part of this architecture. The retail application represents the legacy application. The cashback application and the search application, represent the two new use cases to be addressed without impacting the existing service.
The two base scenarios targeted are, first, the event-driven processing of cashback for every customer purchase according to his/her customer status, and second, allowing the usage of full-text search capabilities for data that is still maintained via legacy application.
3.1. Scenario: Cashback Wallet
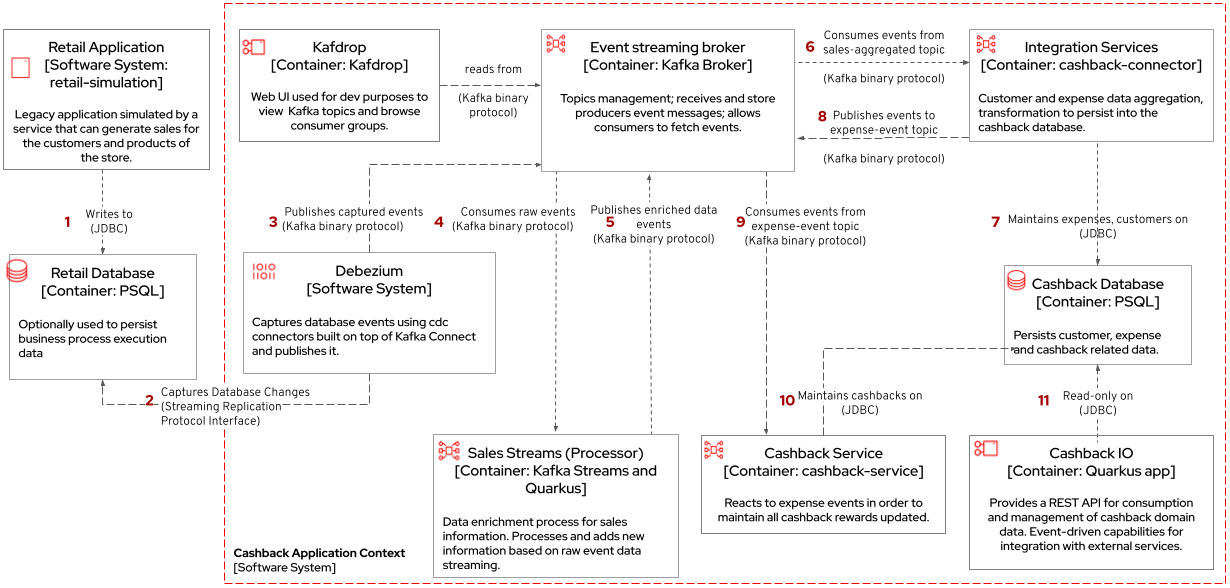
a) Cashback Wallet: A new microservice implements new capabilities enabled by data integration. This integration happens via database event streaming and processing from legacy database to the new cashback database.
-
The cashback processing kicks-off when a new purchase is registered via legacy application. In the demonstration implemented for this solution pattern, we use a service to simulate purchases and register them in the database.
-
Debezium will capture all changes in the database tables below;
-
List of tracked tables in retail database:
public.customer,public.sale,public.line_item,public.product
-
-
Next, Debezium streams the data them over to Kafka. The event streaming solution can be hosted on-premise or on the cloud. In this implementation, we are using AMQ Streams, Red Hat’s Kubernetes-native Apache Kafka distribution.
-
An integration microservice,
sales-streams, reacts to events captured by Debezium and published on three topics, respective tosale-change-eventandlineitem-change-event. -
Using Kafka Streams, the service aggregates multiple events that correlates to a unique purchase. The service will calculate the total amount of the purchase based on individual items price captured, and will publish the enriched data to the topic
sales-aggregated. -
Another event-driven microservice is responsible for tracking customer’s change streamed by Debezium, and for reacting to new enriched sales information - in other words, reacting to data processed by the
sales-streamapplication. -
The service synchronizes
customersandexpensesin the cashback database. This database used to store new cashback feature-related data. -
Once the
cashback-connectormicroservice finished its operations, it will notify the ecosystem that a new or updated expense is available - especially for cashback-processing. A new event is published to anexpense-eventstopic so that interested (subscribed) services can act if needed. -
Now that every information is synchronized in the cashback database, the system can calculate and update any incoming cashback amount the customer earned when purchasing products. The choreography goes on as the
cashback-servicejumps in and reacts to theexpense-eventstopic.-
This microservice is reponsible for the calculation of the cashback based on a customer status, and for making sure the customer will earn a percentual relative to each expense amount. Every customer owns a Cashback Wallet, in other words, all incoming cashback can be accumulated and used later. Since this service is responsible for integrating services in a cloud environment, the technologies used in the demo implementation are Camel, with Quarkus as the runtime.
-
-
With the values properly calculated, the
cashback-servicepersists cashback-related information, including new cashback wallets for first-time customers, incoming cashback for each single customer’s expense, and total cashback. -
The user can visualize cashback data using a sample application
cashback-ui, which runs with Quarkus and uses Panache Rest to handle persistence and expose REST endpoints. Information is finally displayed through an angular-based page. This application is used in the demo to help developers visualizing the demonstration results.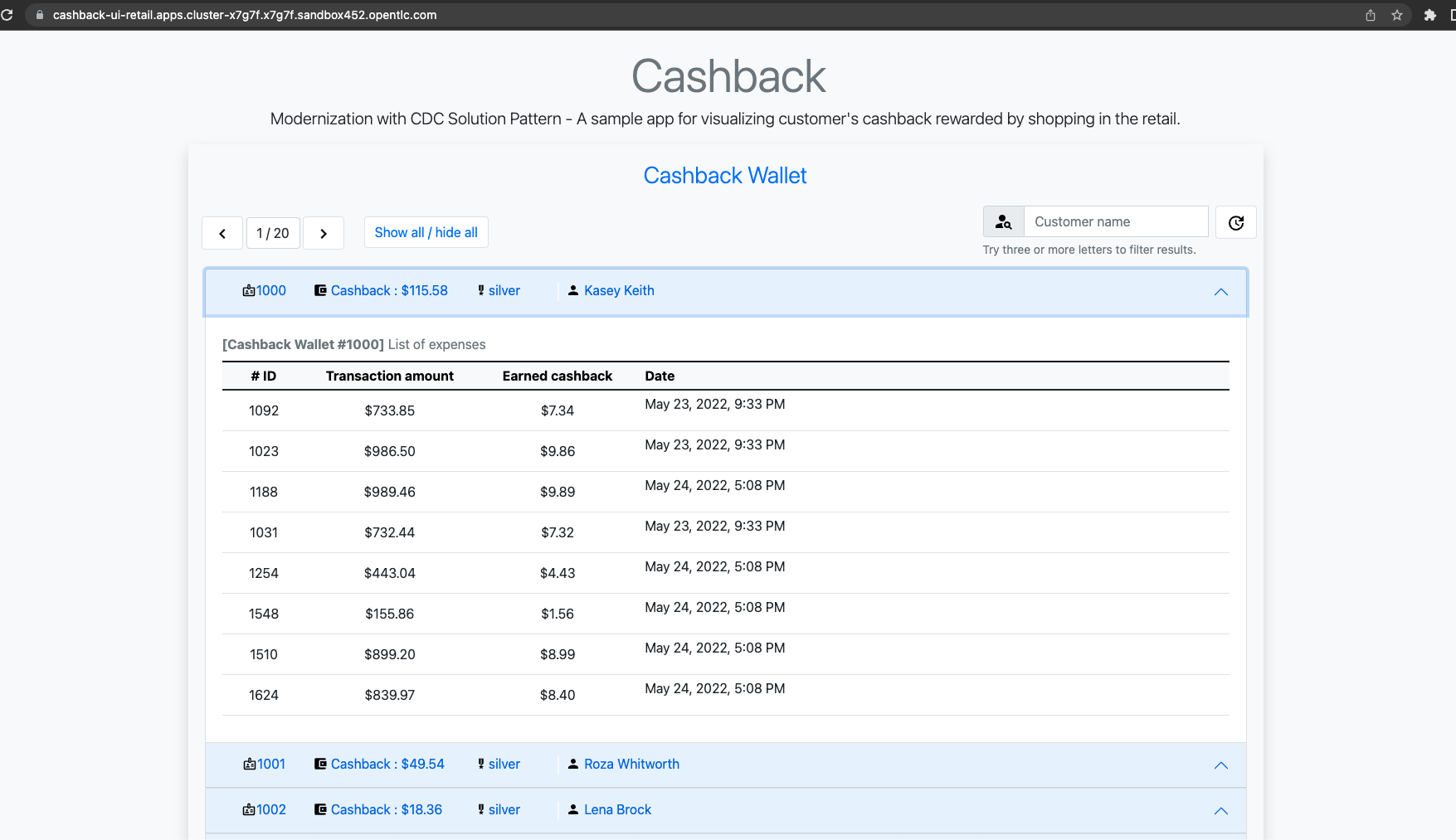 Figure 3. Cashback Wallet UI: sample demo ui for easier data visualization when trying the solution pattern implementation.
Figure 3. Cashback Wallet UI: sample demo ui for easier data visualization when trying the solution pattern implementation.
3.2. Scenario: Full-text search for data in legacy database
b) Full-text search of legacy data: enables full-text search for legacy data by adopting data integration through event streaming and processing. All changes to the legacy database tracked tables, including the operations create, updated and delete, should be reflected in the search index tool. The indexing tool will then store and index data in a way that supports fast searches.
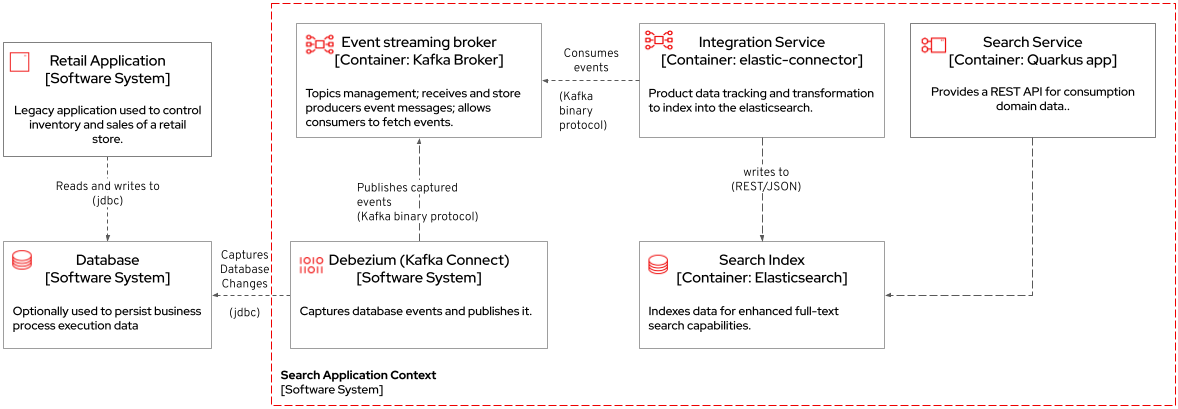
Similarly to the behavior of the cashback scenario, here Debezium is tracking changes in the retail database. All changes to product data is streamed to Kafka. The elastic-connector service reacts to product events and synchronizes it within ElasticSearch product index.
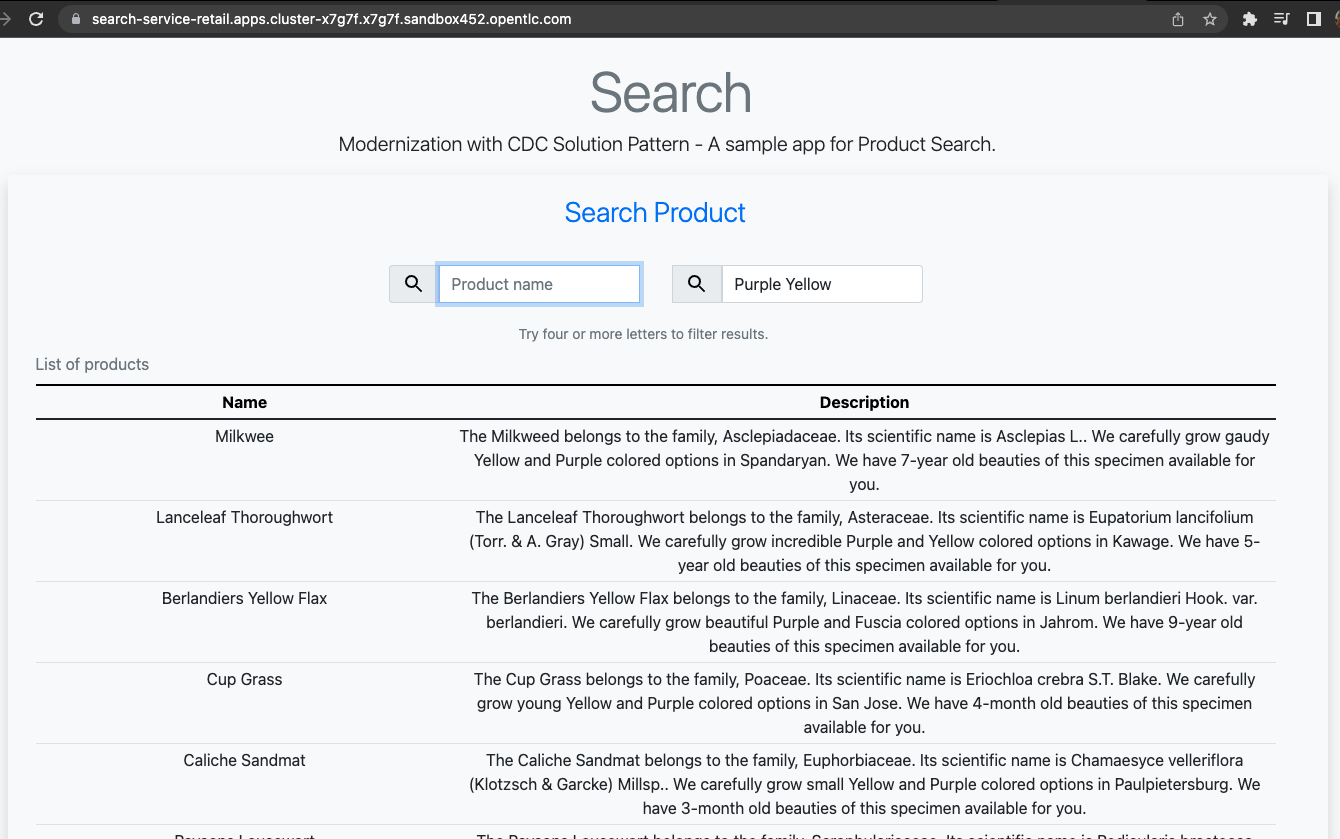
For demonstration purposes, the search-service holds a sample UI to allow searching data in the indexing tool.
The following services are part of this scenario:
-
Retail database: stores all information from the legacy application. It includes information about products, customers and new sales (detailed through line items).The tables in this database are tracked by Debezium.
-
Debezium: tracks all events that happens in tables from retail db (public.customer,public.sale,public.line_item,public.product) and streams changes into Kafka streams;
-
Elastic connector service: an event-driven microservice that reacts to products' events and push relevant updates to Elastic. This service capabilities were developed with with Camel and Quarkus.
-
Search service: a sample quarkus service that integrates with ElasticSearch using the quarkus elastic-rest-client extension, and exposes a REST endpoint for searching products by name and description. For demonstration purposes, this service has a page to facilitate visualizing the search results.